
The Five Aggregates in Artificial Intelligence
To help drive home the meaning of the Five Aggregates as I wrote about in Part 1, let’s try an exercise devising a high-level architecture for an Artificial Intelligence mapping to the Five Aggregates. In some ways it could be easier for us to relate to an Artificial Intelligence than our own intelligence since the parts (computers) were created by us. Using our brain to figure out how our brain works is way tougher than using our brain to understand how something that we created works.

The theme of this blog site is Zen/Buddhism from the point of view of a software developer; who finds much insight into ourselves by building software, which are models of things we do. It’s my Zen Art. That is, I research and build “A.I.” systems in the hope of gaining a better understanding into how our consciousness works – as opposed to the businessman’s purpose for A.I. being a dream of incredibly cheap, non-complaining, replicatable, re-programmable workers.
If you’re not a “computer person”, I still think someone with just a casual knowledge of software development could appreciate this high-level exercise of mapping of the Five Aggregates to a hypothetical A.I. architecture.
Before diving into this exercise I’d like to mention that because the frontier of A.I. is rapidly changing at the time of this writing, January 2019. Much of what I write here could be either obsolete, wrong, or very obvious a month from now. So I won’t burden you further by qualifying every other sentence with ” … at the time of this writing …”.
Machine Learning
The term “A.I.” is often interchangeably and incorrectly used with “Machine Learning”. What makes it confusing is that whatever we call A.I. depends upon how you define “intelligence”. And there really isn’t a solid definition. For the sake of this blog, it may be easier to first consider an un-intelligent thing. An un-intelligent thing needs to be told every single detail about what to do. That includes practically all machines such as cars and computers.
It may sound strange to those who don’t know much about how computers work to call it un-intelligent? In workshops I’ve presented on “data mining” topics, there are a couple of things I often say that are obvious when you’re mindful about it, but overlooked as you go about in the normal life frame of mind:
- What is the best thing about computers? They do exactly what you tell them to do. What is the worst thing about computers? They do exactly what you tell them to do.
- What’s obvious to you may not be obvious to a computer. For example, consider the obvious observation that pregnant humans are female. It’s ridiculously obvious to us, but imagine if a computer figured that out all by itself.
It’s not necessarily that a computer itself is stupid. Rather, it’s the way we manually program them into these “intellectually brittle” dead ends. Instead, an intelligence must be self-adaptive in a very ambiguous world.
Currently, there are three major categories of machine learning: Supervised learning, unsupervised learning, and reinforcement learning. They are often presented as three kinds of tools, as if you were deciding between the purchase of a sedan, a pick-up truck, or a van. Rather, the three types of machine learning are three modes of learning, all required by an intelligence.
Before getting into a little analogy about the three modes of machine learning, I’d like to mention a fourth way a computer “learns” – programming. We may refer to propaganda and advertisements “programming” us, but that’s not correct. Rather, we are “trained” through those means. Programming a human would entail opening up our brain and manually wire up our neurons and manually adjust neurotransmitters.
Supervised Learning
Supervised Learning should really be called “Training”. Imagine you’re three years old sitting in your marine biologist mom’s office. You’re looking through a picture book of marine animals. You ask her about each picture, but since she’s busy, she only can glance over and answer with the general class of the animal; fish, mammal, crustacean, etc.
Eventually, you will figure out, find the patterns of what differentiates the mammals from the fishes. You’ll notice the whales and dolphins have tails pointing sideways and sharks have tails pointing up and down. The mammals also have fewer “fins”. If the picture has enough resolution you may notice fish have scales, mammals don’t. In the future, when you encounter such a creature you’ve never seen before, you’ll at least know whether it’s a mammal or fish.
Remember, this is training, not programming. To be programmed, your mom needs to get into your head and wire the neurons up and tune all sorts of other things in there.
Unsupervised Learning
Now, let’s say your mom is incredibly busy and just leaves the three year old you with the book. You’re on your own classifying the animals in the pictures. Without being given any labels for the animals, you may classify orcas and great whites together or blue whales and whale sharks together. Is that wrong? Orcas and great whites are predators of other big critters, blue wales and whale sharks are huge creatures that filter feed little critters.
The trade-off between supervised and unsupervised learning is that the former saves you lots of time learning what humanity already knows, whereas the latter allows you to be creative. Even if some knowledgeable adult were 100% available to teach you via supervised learning, you’re still being trained, not programmed.
Reinforcement Learning
Remember in the movie, City Slickers, where Norman the calf is walking just minutes after being born? No one taught the calf to walk. The calf awkwardly gets on his feet, stands very shaky, starts taking clumsy steps, going through cycles of trying, receiving feedback, adjusting neuron connections in his brain and muscles, trying again. After many fast cycles of this incremental training, the calf can run. That’s reinforcement learning.
The A.I’s Job
Even we mighty humans aren’t “intelligent” about everything. We each have our unique sets of skills, both seemingly natural and learned. So let’s give our A.I. a job. Let’s give this Artificial Intelligence the skill of a CEO of a corporation, an A.I. CEO. Let’s refer to this as an aCEO.
Taking advantage of what computers can do better than brains, the aCEO could be more effective than a human CEO if it could have a superior:
- “Feelers” into all aspects across the corporation.
- Feelers to life outside the walls of the corporation throughout its ecosystem.
- A map of how all the parts relate, inside the enterprise as well as outside in the ecosystem.
Keep in mind too that it doesn’t need to look or act like a human CEO. It just needs to come up with superior plans and decisions and communicate and manage the executions effectively.
If we think of an enterprise as an organism, the CEO, real or artificial, is the brain organ of an enterprise. The entire enterprise is the “body”. The departments are like the other organs. Cash flow is like blood. What the company produces is their job, their livelihood. I guess that makes the human employees like our “gut bacteria”.
As with the human version of the Five Aggregates, the aCEO version is not a “series of five steps to consciousness”. It’s more the “five parts of sentience” where the whole is greater than the sum of the parts . So I present them in numerical order, but do jump back and forth to other parts. The illustration below provides a high-level view of how the five parts relate.
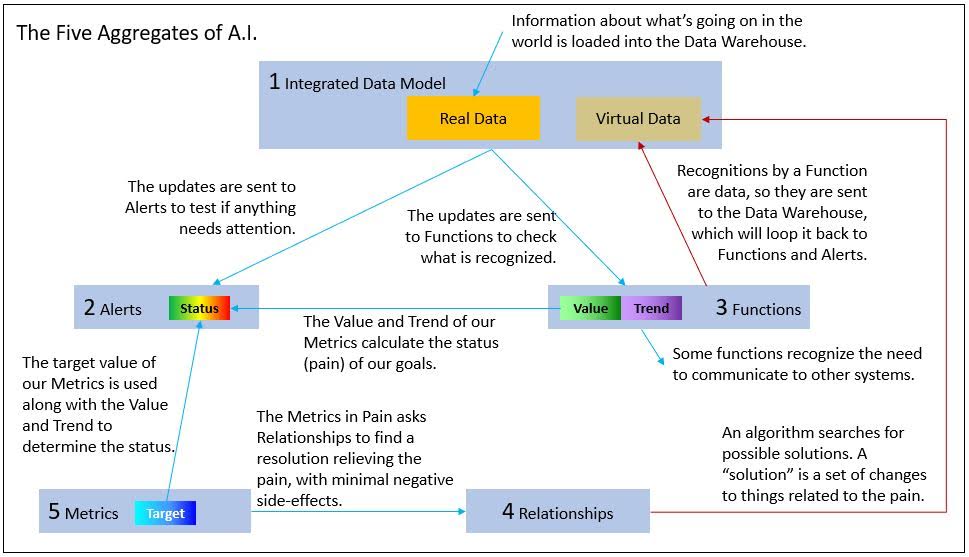
The 1st Aggregate – Integrated Data Model (Body/Form)
The body of the aCEO would of course imply the hardware, the computers. But body/form is much more than that. It’s information about things going on around us. In the Buddhism context, these are “conditioned” forms, the phenomenon that everything is resulting from everything else. The fact that things are moving and interacting means things are impermanent.
So the aCEO needs a way to obtain current data about things related to the business it runs. This current data could be current snapshots or just what has changed since the last time.
At this point, the data coming into the system from its surroundings is raw. To use an analogy based on the old “data mining” term, it’s like mud in a gold pan. But it’s mud from a place we think contains gold, not just randomly looking around. The 1st aggregate also filters out and cleanses most of the mud/crap before it gets to the Perception functions, the 2nd Aggregate. At the end of the 1st Aggregate, five pounds of mud is reduced to a couple ounces of “black sand”.
The 1st Aggregate further does some rough “data prep” on that cleansed data. This data prep organizes the cleansed data to a set of statistics about the data, the composition of values, and even looks for interesting “events” such as spikes in values, trending up or down. Still, this is just data.
This is pretty much where Data Warehouses are at. It encompasses all the processing and massaging of data from many different data sources. But it’s just data at this point – not much different from corn sitting in silos, grown and harvested with a combine. In general, this is where “Business Intelligence” system passes that integrated data to humans to make sense of with their superior Human Intelligence. Human analysts, data scientists, managers. “BI Developers” will author reports using tools such as SQL Server Reporting Services, analysts will visualize data with tools such as Tableau, PowerBI, or even good ol’ Excel. Data scientists could develop predictive models.
The 2nd Aggregate – Alerts (Sensation/Feeling)
Every machine or creature must operate within parameters conducive to its nature, whether it was designed by some intelligence or evolved over time. For example, without special suits (ex. SCUBA gear), humans thrive within strict parameters of atmospheric pressure, temperature, etc.
When it gets too cold, we put on more clothes. When we’re thirsty, we seek water. These are feelings, they are metrics. Your car dashboard is full of them. Going too fast, ease up on the gas pedal.
I make a living as a Business Intelligence consultant, which is all about maximizing performance of a business’ resources. A big part of that is deploying analytics tools conveying metrics to workers of all types – human employees in many roles as well as machines such as computer servers and manufacturing equipment. A tired cliche in my field is “what gets measured gets done”. We call these metrics “Performance Indicators”.
Metrics are determined by executives and “MBA types” and monitored throughout the execution of enterprises processes. Metrics aren’t just a business thing. Practically everything we do involves metrics, from our health (blood pressure, weight, temperature, cholesterol), to driving a car (speed, temperature, distance from other cars), to economic health (unemployment rate, GDP, stock market value).
An example of a business metric, in fact a key metric (called Key Performance Indicators – KPI) is Revenue Growth. What’s interesting about revenue growth is that no growth is usually bad, but too much growth can be bad too. Sometimes we need to limit growth to give the infrastructure time to catch up. Growth that’s too fast can overwhelm the infrastructure leading to mistakes, which lowers quality, which pisses off customers, which sends them away, which lowers revenue.
So a metric is more than a measurement, just one number. It’s more than simply stating Revenue growth is 10% over this time last year. Because too little or too much can be bad, a metric includes a component called a target, in this case, something like 5% growth, no less and no more.
Another component of a metric is a trend. Is the metric trending upwards, downwards, or steady? This is important to know because nothing stays still. Imagine your revenue is trending up and today it’s at goal, but it’s still trending up, which means tomorrow it won’t be where you want it.
The most interesting component of a metric is the status. Remember, too little or too much is bad. But we can live with a margin of error, say 2% on either side. So anything within 3% to 7% is good, from between 0% and less than 3% or greater than 7% and less than 10% is not good. But less than 0% or greater than 10% is bad. In general, the good, not good (warning), and bad are represented by green, yellow, or red icons.
The status of metrics are analogous to our feelings in the human 2nd Aggregate – pleasant, unpleasant, or neutral. The 2nd aggregate is interested in the status value of the metrics mostly so we know what needs attention – correction. In other words what metrics are in a bad (painful) status? In contrast, the target is the domain of the 5th Aggregate, the goals/objectives of the enterprise.
As with our human feelings, there are very many metrics (sometimes thousands) monitored in an enterprise. Some are very high level, such as Revenue Growth and Profit. But most are lower level, for example, the uptime of the reporting system, minimizing office break room expenses, and maximizing employee retention.
Before heading into the 3rd Aggregate, let’s review the process for a human. When pains are felt in the 2nd Aggregate, the 3rd Aggregate tries to recognize what’s going on, the web of goals/desires/beliefs of the 5th Aggregate engage the thoughts of the 4th Aggregate to make everything in the 5th Aggregate happy.
The 3rd Aggregate – Functions (Perceptions)
The 3rd Aggregate is mostly what we’re familiar with in regard to software systems of today. Software systems of today are machines automating some well-defined and tedious job at a really large scale.
If the job that software is automating was not well-defined, not highly predictable, we humans wouldn’t be able to encode the rules as software. But the real world outside of today’s somewhat totalitarian corporate culture is not highly predictable. That world outside is made up of countless independent things, at least seven billion of them with minds of their own. This is where Artificial Intelligence differs from conventional software. Intelligence deals with ambiguity and complexity.
Software today is made up of a designed (meaning “human-crafted”) web of designed functions. Functions take inputs, do some processing within the confines of a “black box”, and output an answer. Examples of computer functions range from something as simple as addition – takes in two numbers, adds them, and output the sum – to something as complicated as an image processor that takes in a picture, does a lot of processing, and outputs where it calculates what are faces, bananas, and cars.
It’s OK for now to let humans write logically tough functions. It beats the hell out of evolution which does things on its own time – like millions of years. But we still need the ability for a large percentage of the functions to self-organize, organize without human intervention. An A.I. consists of so many functions and require constant updating. It would be an insane nightmare for programmers to maintain that much, yet, that’s pretty much how software is currently maintained.
A general purpose programming language (for example, Java, C++, C#) is intended to encode a model of the world that is runnable by a computer. Because the world is so complex, programming languages must be very versatile. So programming by humans is tough. However, Nature found a way for the human brain to model the world. Our neurons wire according to what we’re exposed to at the time and place of our life.
So programming is hard. We try to mitigate that difficulty by creating specialized programming languages on top of specialized software. For example, SQL is a programming language limited to creating, reading, updating, and deleting rows from a table. Of course, there are libraries of packaged functions preventing “reinventing” of code that works across a wide array of applications.
Functions are machines, whether little or big, simple or complicated, natural or man-made, material or encoded. They all take in some inputs and output something. For example, a coffee machine that takes in water, ground coffee, and electricity, and outputs hot coffee. A single neuron is a function. It accumulates charge from many synapses on its dendrites, and at some very complicated point it “fires” a charge out on its axon.
Functions share a couple of very important characteristics. They shield we civilians from the intricacies (nice way of saying “yucky guts”) of how they really work. Imagine if we were required to know all there is to know about building and repairing a car and all its parts in order to drive one. The car’s guts are encapsulated in a tidy package for we civilians such that we just need to know five things; turn on/off, shift gears, gas, brake, steer.
Another important characteristic of functions is for a specific input always return the exact same output. Machines would be impractical to use or even useless to us if they weren’t predictable. Imagine what it would be like if the amount we stepped on the gas pedal fed gas into the engine in a linear manner as usual, but sometimes exponentially, sometimes according to the angle of the sun at the time of day.
That would be a dangerous car to take on the road! I’d be forced to drive very slowly because I never know when the function of the gas pedal will change. Therefore, I can’t go on the freeway because I’m forced to drive slowly. Do you see how any unpredictability drastically makes like tougher?
If a function does the exact same thing for the exact same input, complexity and risk are mitigated … even though complexity and risk can never in practice be eliminated, but at least on paper. Our example of the gas pedal only offered three different outputs and already I wouldn’t drive such a car.
All of our machines, including software 1, are composed of functions. Machines are a composition of parts, where each part does it’s thing and only its thing. Functions made of functions made of functions … However, the functions composing most of our software today do not have the quality of firing out the same output for the same input.
Note that a very interesting class of functions are those so-called “Machine Learning” (ML) models discussed towards the beginning of this blog. These are the product of “data scientists”, functions for guessing things such as how many people in a given population are at risk for becoming diabetic. Input whether you’re obese, over 45, high blood pressure, etc, and it guesses if you’re at risk for becoming diabetic.
They are often incorrectly referred to as Artificial Intelligence. Those functions are just machines. As is typical for machines, they beat the hell out of human effort as long as the rules don’t change.
So imagine again what it would be like if the gas pedal on a car didn’t react the same way for an amount the pedal is pushed down. Perhaps there is a rhyme or reason for its erratic behavior. What else is going on around us when the gas pedal responds to our foot pressure as usual versus when otherwise? This is the purpose for thought, the 4th Aggregate.
The 4th Aggregate – Relationships (Thoughts)
When our collection of functions in the 3rd Aggregate encounters something it isn’t designed for, it throws an exception an error message. Or if it’s a tangible machine, it may “crash and burn”. Usually, human programmers are alerted to these exceptions. They find the cause, use their human intelligence to formulate a solution, and implement it (modify and re-compose the functions).
As discussed towards the end of the 3rd Aggregate, to find a solution for a problem, humans search through webs of relationships – associations we’ve learned over our life. In the field of A.I. and neurology, there is the saying, what fires together, wires together. These relationships include:
- Correlation – These are events that occur together to some degree. The simultaneous occurrence may be coincidence, due to another factor, or does indeed imply some sort of cause and effect.
- Perceived cause and effect 2 – This is anything where we believe one thing will follow another because it has happened a lot.
- Intended cause and effect – These are cause and effect of our human-engineered machines. We intend for gas to explode in cylinders, driving a transmission, that ultimately spins wheels.
For software, such relationships have traditionally been programmed by people. These are procedural relationships. However, in this Big Data age, relationships are wrested from a large history of facts by statistical algorithms.
Thoughts, whether human or machine, are about wonder, “what-if”. The human or machine then investigates what if by playing around with the web of relationships in the heads or in a graph database.
For example, in these pre-A.I. days, the process for optimizing something like low sales goes like this:
- A sales manager experiencing low sales (pain in the 2nd Aggregate) would wonder what to look for in a customer most likely to purchase a luxury car now. That way, the sales personnel can maximize their sales performance (a goal of the 5th Aggregate) by spending more time with such people.
- A data scientist will then run years of sales history and customer demographics through some sort of “machine learning” algorithm. That sales history and demographics data could be thought of as “sensed” in the 1st Aggregate.
- The output of the algorithm are relationships between various customer attributes – gender, education level, age, income level, etc. This set of relationships is then deployed into production as a function (3rd Aggregate) of the enterprise, no different from anything we know to do as a human.
As it is for a human, the 4th Aggregate is the web of relationships as well as the process of finding possible solutions to a pain detected in the 2nd Aggregate. It’s not really that hard to trace a line of relationships when the dots are all connected. What is hard is finding a solution that minimizes negative side-effects. What are negative side-effects? Those are goals and desires that are hampered, the 5th Aggregate.
The 5th Aggregate – Metrics (Consciousness)
Like human creatures, corporate enterprises have goals, missions, and feel “pain”. Some of these corporate goals keep us from breaking laws and there are goals towards growth and higher profits. Goals not doing well register as pain. Metrics (nodes) statuses tie to functions of the 3rd Aggregate – think of these as pain and joy receptors. The web of these goals dictates the “values” or character of the system.
Businesses are founded upon strategies. Strategies are a web of “cause and effect”, a theory that if we perform some action, there will be a chain of effects leading to the satisfaction of our goals. For example, in the 2nd Aggregate, I mentioned Revenue Growth as a key metric. However, Revenue Growth itself isn’t a good thing. We could increase revenue easily by slashing prices, increasing revenue, but lowering profit – and increasing volume, which increases expenses, which also lowers profit.
The illustration below shows a simple strategy map for a doctor’s office. If the practice adds a doctor, that leads to more billable hours, which contributes to higher utilization which leads to higher revenue, which contributes to higher profit.
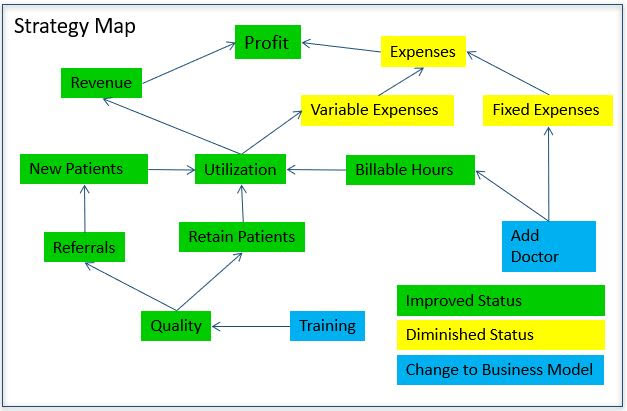
The strategy map above illustrates the trade-offs taken for some action represented by the blue boxes. If it weren’t for the fact that more doctors cost more (in many more ways than just salary), we could simply add as many doctors as possible to make as much money as possible. But there’s always trade-offs.
The complex world in which the aCEO must thrive goes way beyond such simple trade-offs. There are cascading webs of cause and effect that make almost everything hard. For example, the task of something as universal as hiring is so complicated that every business has a specialized Human Resources department. Do candidates have a long list of required skill, required education, are they trustworthy, will they get along with everyone, will they be assertive when necessary, cooperative otherwise?
A more realistic strategy map would be a big unwieldy mess, impractical as a visualization for our human brain. Fortunately, handling such a web of relationships is something computers can do better than us!
Each item is an issue because it interferes with some goal or another. Such magical employees meeting all requirements are rare and so delicate trade-offs (compromises) are made that will hopefully make all goals reasonably “happy”.
Because things are always changing in a business ecosystem, the aCEO will always be “buzzing” like a human brain dealing with constant change. A consciousness isn’t some static picture, but an in-motion process. It’s a process that goes something like this:
- Things in the world change (1st Aggregate) …
- Which could result in pains (bad KPI statuses in the 2nd Aggregate) …
- As well as invalid results from functions in the 3rd Aggregate …
- Which results in goals in the 5th Aggregate trying to minimize pain, re-balance itself …
- And the 5th Aggregate employs the web of cause and effect in the 4th Aggregate to find candidate solutions, and test them out.
Exploring for a set of measured trade-offs that will eventually satisfy all goals, a solution to a minimizing pain, is actually the relatively easy part. Much tougher is organizing the map of relationships in the 4th and 5th Aggregates, connecting the dots. “What” is usually an easier question to answer than “How”.
The biggest breakthrough in software will not be further improvements in accuracy, speed, and volumes of data processed with well-defined tasks. It will be the ability to re-program itself, self-organize the connected dots.
From a Buddhist perspective, software today is dukkha, incapable of adapting itself to constant change. Software today is mostly rather “hand-wired” organizations of functions – meticulously hand-coded by highly-skilled human programmers. And that’s starting to change.
Notes
1 It’s not exactly correct to say that software is composed of functions since what appear to be functions (at the time of this writing) can return different results since it depends upon circumstances outside its inputs and/or the functions often do not handle exceptions (inputs it wasn’t designed to take in) well enough. Those two inadequacies account for much of the reason software has so many bugs. There is a movement towards “functional programming” that enforces at least the first issue, towards the goal of writing software that is less complex.
2 Any time I utter the phrase “cause and effect”, someone reminds me that “correlation does not imply causation”. I don’t think anyone actually does think correlation implies causation. It doesn’t make sense to do something for an effect unless you believe there would be the desired effect. Whatever decisions that are made by people of sound mind are based upon what they perceive to be cause and effect relationship.
